
Introduction
The repeated median algorithm is a robust method for fitting a line to sample points, and forms the basis for most data science applications in the AFA platform.
In this approach, the steps are:
-
The median slope, mi, at some point (xi,yi) is calculated from taking the median of the slope against every other point in the dataset (yj-yi)(xj-xi).
-
The slope from the repeated median algorithm, M, is the median of mi.
-
The y-intercept can be calculated from the median of (yi - Mxi)
Discussion
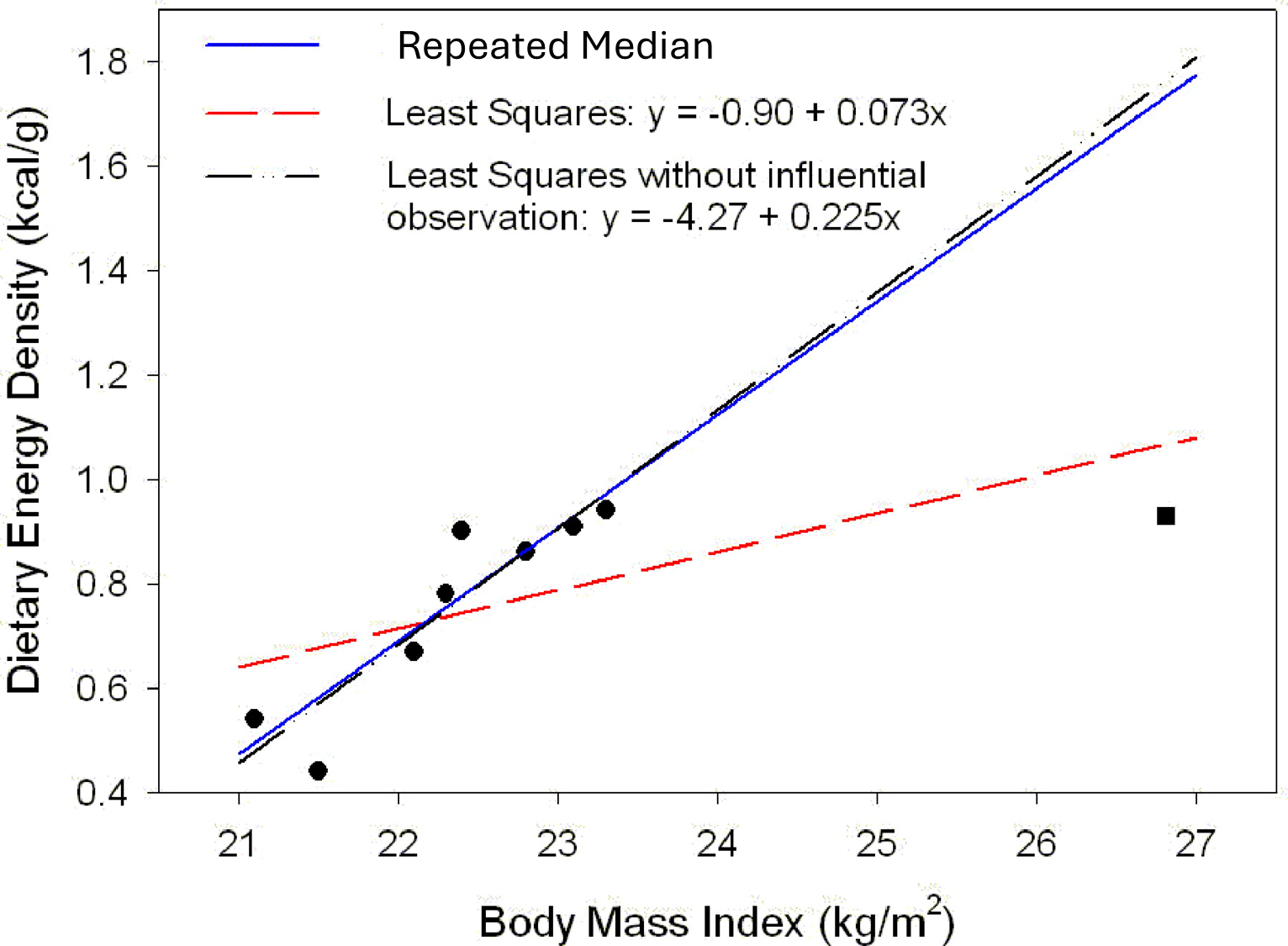
The estimator has a beak-down of 50%. In practical terms, the method can handle data with up to 50% erroneous values (or outliers) without substantial impact to the calculated output. For comparison, in traditional least squares reduction, the break-down point is 1/n, meaning that a single outlier can have substantial impact on results (unless perhaps using a massive data set compared to the number of outljiers).
Below is an idealised example of the impact of a few outliers on fitting using least squares as well as the Repeated Medians approach.
References
-
Siegel, Andrew F. (1982), "Robust regression using repeated medians", Biometrika, 69 (1): 242–244,